- Published on
Request Retries In Distributed Systems - Balancing Resilience and Resources
- Authors

- Name
- Femi Alayesanmi
- @alayesanmi
Building a resilient system with request retries can become an internal DDoS attack on your resilient system. Don't vibe code retries, architect it expecting things to go wrong!
System resilience is super important when building open or closed systems and resilience most times means request retries.
Simple logic:
- Attempt a request
- On Failure, retry the request.
Logically, this looks OK — making sure every request gets successful eventually. But no way! Its not this simple, in fact it can be costly if not done properly depending on your system's use case.
Real Life Example
Considering an open system — a public api for money transfers. The money transfer service has a 99.99% uptime service level agreement (SLA) with external clients using the service, making the following decisions necessary for the system:
- Multiple provider integrations.
- Failover strategy to ensure the success rate of the public api is not completely dependent on the state of individual transfer providers.
- Clients are also advised to retry explicitly failed requests but first confirm the status with a status endpoint, before initiating a retry.
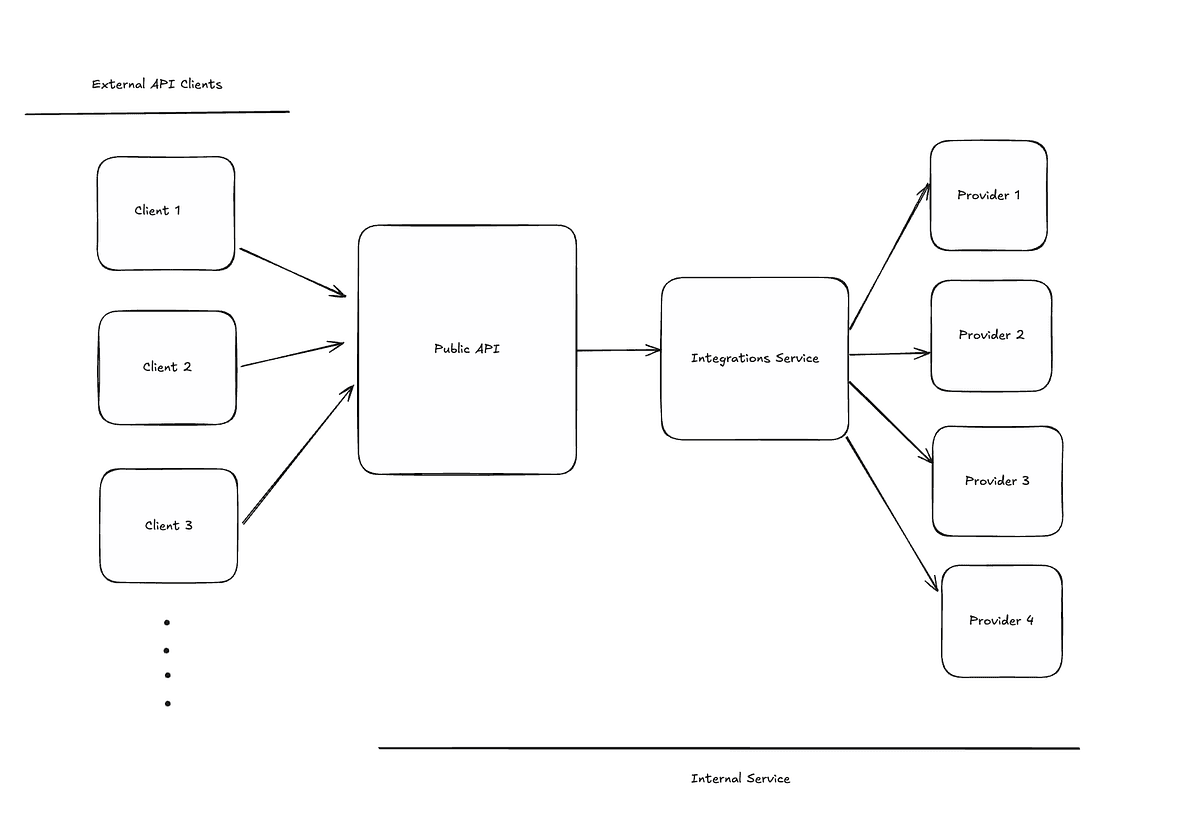
All necessary engineering decisions considered above are valid. However there are some failure points and potential problems worth mentioning, when the unexpected happens in the system. Four major potential problems are:
- Duplicate Transfers: Allowing POST request retries from clients can cause duplicate transfers, resulting in a beneficiary being credited multiple times for one transfer request😭.
- Resource Spikes: During downtime, client retries can create a request surge that can potentially spike resource usage. This makes the service recovery difficult, especially if the outage was already caused by high load.
- Status Check Failures: The endpoint for checking a transfer status will also most likely time out during the same service downtime, rendering it ineffective when needed most.
- Provider Throttling: A high volume of retries and status queries during an outage, can cause the service providers to throttle or block the money transfer integration completely ❌.
Retries with exponential backoff, jitters and even delays cannot completely mitigate these problems. In fact circuit breakers cannot too, because falsely shutting down a valid request due to a certain percentage of failure rate is not good for business (depending on the use case)!
Safe and Efficient Request Retries
Idempotency
Idempotency is a fundamental concept for building distributed systems and request retries is one of the reasons it is very important. One efficient way to achieve idempotency is to ensure every request has a unique identifier from the client (a unique reference).
However, a unique identifier from the client is not sufficient for safe retries within the entire system - a system generated unique checksum with the request metadata is also important for safe service to service internal communication and retries. The checksum essentially ensures every request is treated as a single, indivisible unit within the system.
For example: If the public api service in our money transfer system retries a request to the integration service because it could not get a response on first attempt, the checksum generated for that request helps identify the request and track the current state of the request before processing the retry. The metadata attached to the request checksum will help prevent duplicate transfer requests to the service provider - avoiding duplicate transfers.
Avoid Nested Request Retries
Considering the system example above. The expectation of the system is that individual components of the system are deployed and treated as independent entities, however these components depend on each other and it can be a nested dependency chain.
For example:
=> Public API Service
=> Authentication Service
=> Notification Service
=> Integration Service
=> Transfer Provider 1
=> Transfer Provider 2
=> Wallet service
=> Authentication Service
=> Notification service
=> Notification service
=> Email Dispatcher
=> SMTP Provider
=> Webhook Dispatcher
This is a typical real world micro service high level architecture. Let's consider this scenario:
- on a successful transfer request an email and webhook notification is expected to be sent for confirmation on the client's end
- however in this case, the email and webhook dispatchers are not available due to a resource issue, therefore each requests is retried continuously for a fixed number of times - in this case 5 times with 1 minute interval.
This scenario, will cause a nested retry situation as individual request assumes its the only request failing and each service layer in the system assumes it can independently retry a failed request.
For 1 transfer request completed
Public api
=> notification service (x5 requests)
=> email dispatcher dispatcher (x5 requests)
if available but request is still failing
=> smtp provider (x5 requests)
if not available
=> dispatcher service has will have a request surge handling 5 requests sent for 1 transfer
Imagine if the dispatcher service receives N concurrent requests continuously during this downtime there would be a collision of requests with retries leading to a resource spike in the service, and recovery will be difficult.
This is a typical example of a nested retry situation:
Public API => notification service => email dispatcher => smtp provider
5x 5x 5x
This can be avoided, such that only the parent service bears the retry request (in this case the notification service). Request to the service dependencies in the chain, should only be attempted if they are confirmed available to handle the retry requests otherwise only the notification service should bear the retry load. This reduces the impact of the high load traffic from request retries on the entire system.
Caching with Request Retries In Mind
Improving system resilience and reducing the load that often triggers request retries requires caching as an essential component of the system. Some key caching strategies to consider:
- Cache Static or Frequently Accessed Data: It’s too expensive to always re-run database queries or make external HTTP requests for static or frequently accessed data. Caching these kind of data in an in-memory database like Redis, not only improves API response time, it also reduces the amount of resource utilisation required to retrieve these data for an actual request or retry request.
- Store Request Context In Cache or Database: Consider this algorithm to complete a transfer in the Money Transfer API:
To complete a Transfer Request:
1. Confirm central account balance is sufficient for Transfer
2. Hold transfer amount in central account
3. Initiate Transfer to beneficiary via Provider (HTTP Call)
4. On successul transfer to beneficiary
- Debit held amount from central account
- Return success response to Client
5. On failed transfer to beneficiary
- Release held amount
- Return failed response to client
Of course the transfer flow is not simple, it has different phases and multiple failure points. Therefore, it is important to keep track of each phase of the request in cache and (or) database such that if same request is retried by the client — the request lifecycle should continue from the current state of the request tracked in the cache and (or) database.
- Retry Token: The idea here is to efficiently manage request retries by avoiding processing of N retries from N retry requests. It could also be considered as a rate limiting strategy, where the server has a max number of retry tokens and once it is exhausted no retry is accommodated by the service. However, there has to be a separate process that occasionally adds back retry tokens depending on service availability and other factors. This process prevents a "retry storm" when there is a downtime with the public api or an internal service. The retry tokens can also be managed on the client side to control how retries are sent to the server (preferable for internal server to server communications), this helps to avoid overloading the server with endless retries from a infinite requests during a downtime.

Retry With Complete Context
What is a resilient system without properly logging the complete context of each request? The benefits of this is life-saving, It should be the first point to consider but let’s save the best for the last! 🙂↔️
However it does not stop at logs — retry dashboards and metrics on a request and system level are also important. It puts perspective to what needs improvements, how improvements are impacting the system and supports swift issues resolution when things go bad.
The request and retry context should answer these questions:
- Why the retry
- When did each retry happen
- How many retry attempts for each requests
- Status and timestamp of each retry attempts for a request
- How many requests were retried
- Retries processing time
- Latency of each retry attempt
- Total latency of requests
- Status and timestamp of the entire request
Final Thoughts
It is super important to treat request retries like an actual system feature, it should be properly thought through with definite mechanisms around how retries should be handled in the system with guard rails in place when things go wrong (especially for distributed systems).
If this is not the case, it could cause a disaster in future. Implement and handle request retries expecting the unexpected to happen.
Every design has its pros and cons — depending on the product use case and other factors, there is really no universal standard for building distributed systems. However, there are fundamental principles worth following — one important principle is to always design and implement components of distributed systems with TRUST issues 🚀🚀